声明:文章转载自公众号「码洞」,作者「老钱」。
首先,某头条的文章量、用户量都是很大的,点击量那就更恐怖了。
请问,如果实时展现热门文章,比如近 8 小时点击量最大的文章前 100 名。如果是你来开发这个功能,你怎么做?
这个好办啊,redis 一个 sortedset 搞定啊,score 计数,key 是文章 ID,不就 ok 了么?
回答的不错,你可以走了!
要听清题目,说好的 8 小时动态时间窗口,计数是会过期的。还有,头条的量有这么小么,一个 redis 就搞定了?同学啊,我告诉你,文章的量你起码得估计个几十万,用户你得估计几个亿,点击量你至少得估计个 1M/s 吧。
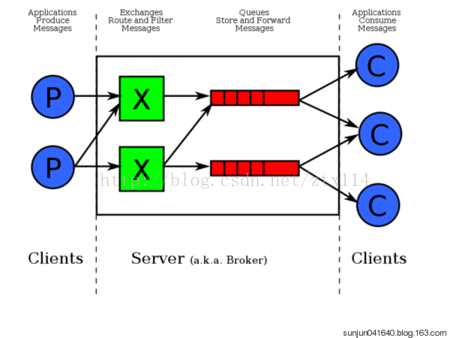
数据接收
1M/s 的点击并发量,肯定是需要分布式了。客户端可能会为了减轻服务器的压力而选择延迟合并点击请求进行批量发送。简单起见,这里就使用 HTTP 协议吧。我们先不考虑恶意用户刷点击的行为。
服务器肯定会有多台机器多进程部署来接受点击请求,接收到的请求在进行参数解析后,被发送到存储单元。为了减轻存储的压力,每个进程可能会使用小窗口聚合数据,每隔一小段时间将窗口内的数据聚合起来一起发给存储单元。
数据存储
点击数据是很重要的数据,用户的兴趣偏好就靠它了。这么大的点击数据如果全部用内存装的话,成本太高。所以别指望完全使用 redis 了。
拿 kafka 存是一个好办法,ZeroCopy 机制并发量很高,数据持久化在磁盘里成本低。不过 kafka 的数据一般是有过期时间的,如果想完全记住用户的点击以便做长期的数据分析,少不了要使用 hdfs 了。
但是因为要做准实时统计,hdfs 可不适合干这个,hdfs 适合做离线统计的数据源。所以还得靠 kafka 接数据,然后消费者一边入 hdfs,一边做实时统计。
实时统计可以使用 spark stream、storm 接受 kafka 的输入,也可以自己手写。
![图片[1]-深度解析某头条的一道面试题-第五维](https://img-blog.csdn.net/20180619150536870?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzI2Njc2MjA3/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
分布式 TopN 算法
用户太多,用户表按用户 ID 哈希分成了 1024 张子表。用户表里有一个字段 score,表示这个用户的积分数。现在我们要计算前 100 名积分最多的用户以及积分数,该怎么查询?
如果是单个表,一个 SQL 也就搞定了
select id, score from user order by score desc limit 100
如果是多个子表,你得在每个子表上都进行一次 TopN 查询,然后聚合结果再做一次 TopN 查询。下面是伪代码
candidates = []for k in range(1024): # 每个表都取topn rows = select id, score from user_${k} order by score desc limit 100 # 聚合结果 candidates.extend(rows)# 根据score倒排candidates = sorted(candidates, key=lambda t: t[1], reverse=True)# 再取topncandidates[:100]
子表查询可以多线程并行,提高聚合效率。
滑动窗口
8 小时的滑动窗口,意味着新的数据源源不断的进来,旧的数据时时刻刻在淘汰。严格来说,精准的 8 小时滑动窗口要求每条数据要严格的过期,差了 1 秒都不行,到点了就立即被淘汰。
精准的代价是我们要为每条点击记录都设置过期时间,过期时间本身也是需要存储的,而且过期策略还需要定时扫描时间堆来确认哪些记录过期了。量大的时候这些都是不容小嘘的负担。
但是在业务上来讲,排行版没有必要做到如此的精准,偏差个几分钟这都不是事。
业务上的折中给服务的资源优化带来了机遇。我们对时间片进行了切分,一分钟一个槽来进行计数。下面是伪代码
class HitSlot { long timestamp; # earlies timestamp map[int]int hits; # post_id => hits void onHit(int postId, int hits) { this.hits[postId] += hits; }}class WindowSlots { HitSlot currentSlot; # current active slots LinkedList<HitSlot> historySlots; # history unactive slots map[int]int topHits; # topn posts void onHit(int postId, int hits) { # 因为上游有合并点击,所以有了hits参数 long ts = System.currentTimeMillis(); if(this.currentSlot == null) { # 创建第一个槽 this.currentSlot == new HitSlot(ts); } elif(ts - this.currentSlot.timestamp > 60 * 1000) { # 创建下一个槽,一分钟一个槽 this.historySlots.add(this.currentSlot); this.currentSlot = new HitSlot(ts); } this.currentSlot.onHit(postId, hits); } void onBeat() { # 维护窗口,移除过期的槽,然后统计topn,30s~60s调用一次 if(historySlots.isEmpty()) { return; } HitSlot slot = historySlots[0]; long ts = System.currentTimeMillis(); if(ts - slot.timestamp > 8 * 60 * 60 * 1000) { # 过期了8小时,移掉第一个 historySlots.remove(0); topHits = topn(aggregateSlots(historySlots)); # 计算topn的帖子 } }}
上面的代码代表着每个分布式子节点的逻辑,因为是伪代码,所以加锁问题就不细写了。它的目标就是定时维持一个 8 小时的统计窗口,并汇聚 topn 的热帖放在内存里。这个 topn 的数据并不是特别实时,有一个大约 1 分钟的短暂的时间窗口。
定时任务
每个子节点都会有一个定时任务去负责维持统计窗口,过期失效的统计数据,计算局部的 topn 热帖。
现在每个子节点都有了各自的局部 topn 热帖,那么还需要一个主节点去汇总这些局部热点,然后计算去全局热帖。
主节点也没必要特别实时,定期从子节点拉取 topn 数据即可,也可以让字节点主动汇报。
class HotPostsAggregator { map[int]map[int]int localTopnPosts; # nodeId => topn posts map[int]int globalTopnPosts; void onBeat() { // do aggregate // save globalTopnPosts to redis } void onLocalReport(int nodeId, map[int]int topnPosts) { // 子节点上报局部热帖 }}
散列
按照头条的文章至少几十万篇,如果每个子节点都要对所有的文章统计点击数,似乎也会占用不少内存,聚合和排序热帖也会有不少计算量。最好的想法是每个子节点只负责一部分文章的统计,这样可以明显节省计算资源。
我们将 kafka 的分区数设置为字节点的数量,这样每个节点负责消费一个分区的数据。在 kafka 生产端,对点击记录的帖子 ID 进行散列,保证相同文章 ID 的点击流进入相同的分区,最终流向同一个统计子节点。
消费者挂了
当机器增多时,节点挂掉的概率也会增大。硬件可能损坏,电源可能掉电,人为操作失误。如果没有做任何防范措施,当一个字节点挂掉时,该节点上 8 个小时时间窗口的统计数据将会丢失。该节点所管理的局部热点文章就丧失了进入全局热帖的机会。
这可能不会对产品和体验上带来很大的伤害,节点重启 8 小时之后也就完全恢复了。而且这 8 小时之内,丧失了部分文章的热点投票权也不会对整体业务带来巨大影响。
但是我们都希望系统可以更加完美一点不是么?当节点挂掉时,我们希望可以快速恢复状态,这也是可以做到的,难度也不是很大,不过是定时做一下 checkpoint,将当前的状态持久化到本地文件或者数据库中。因为每个子节点管理的文章不会太多,所以需要序列化的内容也不会太大。当节点重启时,从持久化的 checkpoint 中将之前的状态恢复出来,然后继续进行消费和统计。
如果你使用的是 spark-stream,它内置的 checkpoint 功能会让你实现备份和恢复会更加简单,更加安全。
如果你不想做 checkpoint,办法还是有的,就是可能耗时旧一点。那就是对 hdfs 中的存储的所有的点击流数据进行一次 mapreduce,将 8 小时窗口内的点击流的点击量统计出来,然后想办法导入到字节点进程中去。
这要求 hdfs 的数据也是散列存储的,和 kafka 对应,这样可以快速圈出需要统计的数据范围。也许会因为 mapreduce 本身会耗时一点时间,最终导致恢复的数据没有那么准确,不过这关系也不大,我们用这样粗糙的方法,能对得起那 9.5 成的数据已经做的很不错了。
点击去重
上面讲了一堆堆,代码敲了不少图画了不少,似乎很有道理。但是还有个重要的没提到,那就是点击去重。如果一个用户反复点击了很多次,那该如何计数比较合理。
一篇好的文章如果它不是太短的话,一般会吸引读者反复阅读很多次。这个计数如果完全去重了记为一次似乎也不太合理。但是如果是故意被人反复点击而被记了太多次明显也不好。那该如何选择呢?
首先要从客户端下手,客户端本身可以过滤一部分无效点击。同一篇文章在太短的时间内被当前用户反复点击,这个模式还是很好发现的。如果间隔时间比较长,那就是读者的回味点击,属于文章的正向反馈,应该记录下来。
客户端做好了,然后再从服务器端下手,服务器端下手就比较困难了。要探测用户的行为模式意味着要对用户的行为状态化,这样就会大量加重服务器的存储负担。
服务器还需要防止用户的防刷行为。如果缺失防刷控制,一个头条号可以通过这种漏洞来使得自己的文章非法获得大量点击,进入热门文章列表,打上热门标签,被海量的用户看到,就会获得较大的经济效益,即使这篇文章内容本身吸引力并不足够。
当用户发现这样差劲的内容也能上热门榜单时,无疑会对产品产生一定的质疑。如果这种行为泛滥开来,那就可能对产品造成比较致命的负面影响。
防刷是一门大型课题,本篇内容就不做详细讲解了,笔者在这方面也不是什么专家。简单点说放刷本质上就是提取恶意行为的特征。常见的策略就是同一篇文章被来自于同一个 IP 或者有限的几个 IP 的频繁点击请求,这时就可以使用封禁 IP 的招数来搞定。还可以使用用户反馈机制来识别非正常的热门内容,然后人工干预等。业界还有一些更高级的如机器学习深度学习等方法来防刷,这些读者都可以自行搜索研究。